Table Of Contents
- Werkzeug Tutorial
- Part 0: The Folder Structure
- Part 1: The WSGI Application
- Part 2: The Utilities
- Intermission: And Now For Something Completely Different
- Part 3: Database Models
- Part 4: The View Functions
- Part 5: The Templates
- Intermission: Adding The Design
- Part 6: Listing Public URLs
- The End Result
- Bonus: Styling 404 Error Pages
- Outro
Werkzeug Tutorial¶
Welcome to the Werkzeug 0.5 tutorial in which we will create a TinyURL clone that stores URLs in a database. The libraries we will use for this applications are Jinja 2 for the templates, SQLAlchemy for the database layer and, of course, Werkzeug for the WSGI layer.
The reasons why we’ve decided on these libraries for the tutorial application is that we want to stick to some of the design decisions Django took in the past. One of them is using view functions instead of controller classes with action methods, which is common in Rails and Pylons, the other one is designer-friendly templates.
The Werkzeug example folder contains a couple of applications that use other template engines, too, so you may want to have a look at them. There is also the source code of this application.
You can use easy_install to install the required libraries:
sudo easy_install Jinja2
sudo easy_install SQLAlchemy
If you’re on Windows, omit the “sudo” (and make sure, setuptools is installed); if you’re on OS X, you can check if the libraries are also available in port; or on Linux, you can check out your package manager for packages called python-jinja and python-sqlalchemy.
If you’re curious, check out the online demo of the application.
Part 0: The Folder Structure¶
Before we can get started we have to create a Python package for our Werkzeug application and the folders for the templates and static files.
This tutorial application is called shorty and the initial directory layout we will use looks like this:
manage.py
shorty/
__init__.py
templates/
static/
The __init__.py and manage.py files should be empty for the time being. The first one makes shorty a Python package, the second one will hold our management utilities later.
Part 1: The WSGI Application¶
Unlike Django or other frameworks, Werkzeug operates directly on the WSGI layer. There is no fancy magic that implements the central WSGI application for you. As a result of that the first thing you will do every time you write a Werkzeug application is implementing this basic WSGI application object. This can now either be a function or, even better, a callable class.
A callable class has huge advantages over a function. For one you can pass it some configuration parameters and furthermore you can use inline WSGI middlewares. Inline WSGI middlewares are basically middlewares applied “inside” of our application object. This is a good idea for middlewares that are essential for the application (session middlewares, serving of media files etc.).
Here the initial code for our shorty/application.py file which implements the WSGI application:
from sqlalchemy import create_engine
from werkzeug import Request, ClosingIterator
from werkzeug.exceptions import HTTPException
from shorty.utils import session, metadata, local, local_manager, url_map
from shorty import views
import shorty.models
class Shorty(object):
def __init__(self, db_uri):
local.application = self
self.database_engine = create_engine(db_uri, convert_unicode=True)
def init_database(self):
metadata.create_all(self.database_engine)
def __call__(self, environ, start_response):
local.application = self
request = Request(environ)
local.url_adapter = adapter = url_map.bind_to_environ(environ)
try:
endpoint, values = adapter.match()
handler = getattr(views, endpoint)
response = handler(request, **values)
except HTTPException, e:
response = e
return ClosingIterator(response(environ, start_response),
[session.remove, local_manager.cleanup])
That’s a lot of code for the beginning! Let’s go through it step by step. First we have a couple of imports: From SQLAlchemy we import a factory function that creates a new database engine for us. A database engine holds a pool of connections for us and manages them. The next few imports pull some objects into the namespace Werkzeug provides: a request object, a special iterator class that helps us cleaning up stuff at the request end and finally the base class for all HTTP exceptions.
The next five imports are not working because we don’t have the utils module written yet. However we should cover some of the objects already. The session object pulled from there is not a PHP-like session object but a SQLAlchemy database session object. Basically a database session object keeps track of yet uncommited objects for the database. Unlike Django, an instantiated SQLAlchemy model is already tracked by the session! The metadata object is also an SQLAlchemy thing which is used to keep track of tables. We can use the metadata object to easily create all tables for the database and SQLAlchemy uses it to look up foreign keys and similar stuff.
The local object is basically a thread local object created in the utility module for us. Every attribute on this object is bound to the current request and we can use this to implicitly pass objects around in a thread-safe way.
The local_manager object ensures that all local objects it keeps track of are properly deleted at the end of the request.
The last thing we import from there is the URL map which holds the URL routing information. If you know Django you can compare that to the url patterns you specify in the urls.py module, if you have used PHP so far it’s comparable with some sort of built-in “mod_rewrite”.
We import our views module which holds the view functions and then we import the models module which holds all of our models. Even if it looks like we don’t use that import it’s there so that all the tables are registered on the metadata properly.
So let’s have a look at the application class. The constructor of this class takes a database URI which is basically the type of the database and the login credentials or location of the database. For SQLite this is for example 'sqlite:////tmp/shorty.db' (note that these are four slashes).
In the constructor we create a database engine for that database URI and use the convert_unicode parameter to tell SQLAlchemy that our strings are all unicode objects.
Another thing we do here is binding the application to the local object. This is not really required but useful if we want to play with the application in a python shell. On application instanciation we have it bound to the current thread and all the database functions will work as expected. If we don’t do that Werkzeug will complain that it’s unable to find the database when it’s creating a session for SQLAlchemy.
The init_database function defined below can be used to create all the tables we use.
And then comes the request dispatching function. In there we create a new request object by passing the environment to the Request constructor. Once again we bind the application to the local object, this time, however, we have to do this, otherwise things will break soon.
Then we create a new URL map adapter by binding the URL map to the current WSGI environment. This basically looks at the environment of the incoming request information and fetches the information from the environment it requires. This is for example the name of the server for external URLs, the location of the script so that it can generate absolute paths if we use the URL builder. We also bind the adapter to the local object so that we can use it for URL generation in the utils module.
After that we have a try/except that catches HTTP exceptions that could occur while matching or in the view function. When the adapter does not find a valid endpoint for our current request it will raise a NotFound exception which we can use like a response object. An endpoint is basically the name of the function we want to handle our request with. We just get the function with the name of the endpoint and pass it the request and the URL values.
At the end of the function we call the response object as WSGI application and pass the return value of this function (which will be an iterable) to the closing iterator class along with our cleanup callbacks (which remove the current SQLAlchemy session and clean up the data left in the local objects).
As next step create two empty files shorty/views.py and shorty/models.py so that our imports work. We will fill the modules with useful code later.
Part 2: The Utilities¶
Now we have basically finished the WSGI application itself but we have to add some more code into our utiliy module so that the imports work. For the time being we just add the objects which we need for the application to work. All the following code goes into the shorty/utils.py file:
from sqlalchemy import MetaData
from sqlalchemy.orm import create_session, scoped_session
from werkzeug import Local, LocalManager
from werkzeug.routing import Map, Rule
local = Local()
local_manager = LocalManager([local])
application = local('application')
metadata = MetaData()
session = scoped_session(lambda: create_session(application.database_engine,
transactional=True), local_manager.get_ident)
url_map = Map()
def expose(rule, **kw):
def decorate(f):
kw['endpoint'] = f.__name__
url_map.add(Rule(rule, **kw))
return f
return decorate
def url_for(endpoint, _external=False, **values):
return local.url_adapter.build(endpoint, values, force_external=_external)
First we again import a bunch of stuff, then we create the local objects and the local manager we already discussed in the section above. The new thing here is that calling a local object with a string returns a proxy object. This returned proxy object always points to the attribute with that name on the local object. For example application now points to local.application all the time. If you, however, try to do something with it and there is no object bound to local.application you will get a RuntimeError.
The next three lines are basically everything we need to get SQLAlchemy 0.4 or higher running in a Werkzeug application. We create a new metadata for all of our tables and then a new scoped session using the scoped_session factory function. This basically tells SQLAlchemy to use the same algorithm to determine the current context as werkzeug local does and use the database engine of the current application.
If we don’t plan to add support for multiple instances of the application in the same python interpreter we can also simplify that code by not looking up the application on the current local object but somewhere else. This approach is for example used by Django but makes it impossible to combine multiple such applications.
The rest of the module is code we will use in our views. Basically the idea there is to use decorators to specify the URL dispatching rule for a view function rather than a central urls.py file like you could do in Django or a .htaccess for URL rewrites like you would do in PHP. This is one way to do it and there are countless of other ways to handle rule definitions.
The url_for function, which we have there too, provides a simple way to generate URLs by endpoint. We will use it in the views and our model later.
Intermission: And Now For Something Completely Different¶
Now that we have finished the foundation for the application we could relax and do something completely different: management scripts. Most of the time you do similar tasks while developing. One of them is firing up a development server (If you’re used to PHP: Werkzeug does not rely on Apache for development, it’s perfectly fine and also recommended to use the wsgiref server that comes with python for development purposes), starting a python interpreter to play with the database models, initializing the database etc.
Werkzeug makes it incredible easy to write such management scripts. The following piece of code implements a fully featured management script. Put it into the manage.py file you have created in the beginning:
#!/usr/bin/env python
from werkzeug import script
def make_app():
from shorty.application import Shorty
return Shorty('sqlite:////tmp/shorty.db')
def make_shell():
from shorty import models, utils
application = make_app()
return locals()
action_runserver = script.make_runserver(make_app, use_reloader=True)
action_shell = script.make_shell(make_shell)
action_initdb = lambda: make_app().init_database()
script.run()
werkzeug.script is explained in detail in the script documentation and we won’t cover it here, most of the code should be self explaining anyway.
What’s important is that you should be able to run python manage.py shell to get an interactive Python interpreter without traceback. If you get an exception check the line number and compare your code with the code we have in the code boxes above.
Now that the script system is running we can start writing our database models.
Part 3: Database Models¶
Now we can create the models. Because the application is pretty simple we just have one model and table:
from datetime import datetime
from sqlalchemy import Table, Column, String, Boolean, DateTime
from shorty.utils import session, metadata, url_for, get_random_uid
url_table = Table('urls', metadata,
Column('uid', String(140), primary_key=True),
Column('target', String(500)),
Column('added', DateTime),
Column('public', Boolean)
)
class URL(object):
def __init__(self, target, public=True, uid=None, added=None):
self.target = target
self.public = public
self.added = added or datetime.utcnow()
if not uid:
while True:
uid = get_random_uid()
if not URL.query.get(uid):
break
self.uid = uid
@property
def short_url(self):
return url_for('link', uid=self.uid, _external=True)
def __repr__(self):
return '<URL %r>' % self.uid
session.mapper(URL, url_table)
This module is pretty straightforward. We import all the stuff we need from SQLAlchemy and create a table. Then we add a class for this table and we map them both together. For detailed explanations regarding SQLAlchemy you should have a look at the excellent tutorial.
In the constructor we generate a unique ID until we find an id which is still free to use. What’s missing is the get_random_uid function we have to add to the utils module:
from random import sample, randrange
URL_CHARS = 'abcdefghijkmpqrstuvwxyzABCDEFGHIJKLMNPQRST23456789'
def get_random_uid():
return ''.join(sample(URL_CHARS, randrange(3, 9)))
Once that is done we can use python manage.py initdb to initialize the database and play around with the stuff using python manage.py shell:
>>> from shorty.models import session, URL
Now we can add some URLs to the database:
>>> urls = [URL('http://example.org/'), URL('http://localhost:5000/')]
>>> URL.query.all()
[]
>>> session.commit()
>>> URL.query.all()
[<URL '5cFbsk'>, <URL 'mpugsT'>]
As you can see we have to commit in order to send the urls to the database. Let’s create a private item with a custom uid:
>>> URL('http://werkzeug.pocoo.org/', False, 'werkzeug-webpage')
>>> session.commit()
And query them all:
>>> URL.query.filter_by(public=False).all()
[<URL 'werkzeug-webpage'>]
>>> URL.query.filter_by(public=True).all()
[<URL '5cFbsk'>, <URL 'mpugsT'>]
>>> URL.query.get('werkzeug-webpage')
<URL 'werkzeug-webpage'>
Now that we have some data in the database and we are somewhat familiar with the way SQLAlchemy works, it’s time to create our views.
Part 4: The View Functions¶
Now after some playing with SQLAlchemy we can go back to Werkzeug and start creating our view functions. The term “view function” is derived from Django which also calls the functions that render templates “view functions”. So our example is MTV (Model, View, Template) and not MVC (Model, View, Controller). They are probably the same but it’s a lot easier to use the Django way of naming those things.
For the beginning we just create a view function for new URLs and a function that displays a message about a new link. All that code goes into our still empty views.py file:
from werkzeug import redirect
from werkzeug.exceptions import NotFound
from shorty.utils import session, render_template, expose, validate_url, \
url_for
from shorty.models import URL
@expose('/')
def new(request):
error = url = ''
if request.method == 'POST':
url = request.form.get('url')
alias = request.form.get('alias')
if not validate_url(url):
error = "I'm sorry but you cannot shorten this URL."
elif alias:
if len(alias) > 140:
error = 'Your alias is too long'
elif '/' in alias:
error = 'Your alias might not include a slash'
elif URL.query.get(alias):
error = 'The alias you have requested exists already'
if not error:
uid = URL(url, 'private' not in request.form, alias).uid
session.commit()
return redirect(url_for('display', uid=uid))
return render_template('new.html', error=error, url=url)
@expose('/display/<uid>')
def display(request, uid):
url = URL.query.get(uid)
if not url:
raise NotFound()
return render_template('display.html', url=url)
@expose('/u/<uid>')
def link(request, uid):
url = URL.query.get(uid)
if not url:
raise NotFound()
return redirect(url.target, 301)
@expose('/list/', defaults={'page': 1})
@expose('/list/<int:page>')
def list(request, page):
pass
Quite a lot of code again, but most of it is just plain old form validation. Basically we specify two functions: new and display and decorate them with our expose decorator from the utils. This decorator adds a new URL rule to the map by passing all parameters to the constructor of a rule object and setting the endpoint to the name of the function. So we can easily build URLs to those functions by using their name as endpoint.
Keep in mind that this is not necessarily a good idea for bigger applications. In such cases it’s encouraged to use the full import name with a common prefix as endpoint or something similar. Otherwise it becomes pretty confusing.
The form validation in the new method is pretty straightforward. We check if the current method is POST, if yes we get the data from the request and validate it. If there is no error we create a new URL object, commit it to the database and redirect to the display page.
The display function is not much more complex. The URL rule expects a parameter called uid, which the function accepts. Then we look up the URL rule with the given uid and render a template by passing the URL object to it.
If the URL does not exist we raise a NotFound exception which displays a generic “404 Page Not Found” page. We can later replace it by a custom error page by catching that exception before the generic HTTPException in our WSGI application.
The link view function is used by our models in the short_url property and is the short URL we provide. So if the URL uid is foobar the URL will be available as http://localhost:5000/u/foobar.
The list view function has not yet been written, we will do that later. But what’s important is that this function takes a URL parameter which is optional. The first decorator tells Werkzeug that if just /page/ is requested it will assume that the page equals 1. Even more important is the fact that Werkzeug also normalizes the URLs. So if you requested /page or /page/1, you will be redirected to /page/ in both cases. This makes Google happy and comes for free. If you don’t like that behavior, you can also disable it.
And again we have imported two objects from the utils module that don’t exist yet. One of those should render a jinja template into a response object, the other one validates a URL. So let’s add those to utils.py:
from os import path
from urlparse import urlparse
from werkzeug import Response
from jinja2 import Environment, FileSystemLoader
ALLOWED_SCHEMES = frozenset(['http', 'https', 'ftp', 'ftps'])
TEMPLATE_PATH = path.join(path.dirname(__file__), 'templates')
jinja_env = Environment(loader=FileSystemLoader(TEMPLATE_PATH))
jinja_env.globals['url_for'] = url_for
def render_template(template, **context):
return Response(jinja_env.get_template(template).render(**context),
mimetype='text/html')
def validate_url(url):
return urlparse(url)[0] in ALLOWED_SCHEMES
That’s it, basically. The validation function checks if our URL looks like an HTTP or FTP URL. We do this whitelisting to ensure nobody submits any dangerous JavaScript or similar URLs. The render_template function is not much more complicated either, it basically looks up a template on the file system in the templates folder and renders it as response.
Another thing we do here is passing the url_for function into the global template context so that we can build URLs in the templates too.
Now that we have our first two view functions it’s time to add the templates.
Part 5: The Templates¶
We have decided to use Jinja templates in this example. If you are used to Django templates you should feel at home, if you have worked with PHP so far you can compare the Jinja templates with smarty. If you have used PHP as templating language until now you should have a look at Mako for your next project.
Security Warning: We are using Jinja here which is a text based template engine. As a matter of fact, Jinja has no idea what it is dealing with, so if you want to create HTML template it’s your responsibility to escape all values that might include, at some point, any of the following characters: >, < or &. Inside attributes you also have to escape double quotes. You can use the jinja |e filter for basic escapes, if you pass it true as argument it will also escape quotes (|e(true)). As you can see from the examples below we don’t escape URLs. The reason is that we won’t have any ampersands in the URL and as such it’s safe to omit it.
For simplicity we will use HTML 4 in our templates. If you have already some experience with XHTML you can adopt the templates to XHTML. But keep in mind that the example stylesheet from below does not work with XHTML.
One of the cool things Jinja inherited from Django is template inheritance. Template inheritance means that we can put often used elements into a base template and fill in placeholders. For example all the doctype and HTML base frame goes into a file called templates/layout.html:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN"
"http://www.w3.org/TR/html4/strict.dtd">
<html>
<head>
<title>Shorty</title>
</head>
<body>
<h1><a href="{{ url_for('new') }}">Shorty</a></h1>
<div class="body">{% block body %}{% endblock %}</div>
<div class="footer">
<a href="{{ url_for('new') }}">new</a> |
<a href="{{ url_for('list') }}">list</a> |
use shorty for good, not for evil
</div>
</body>
</html>
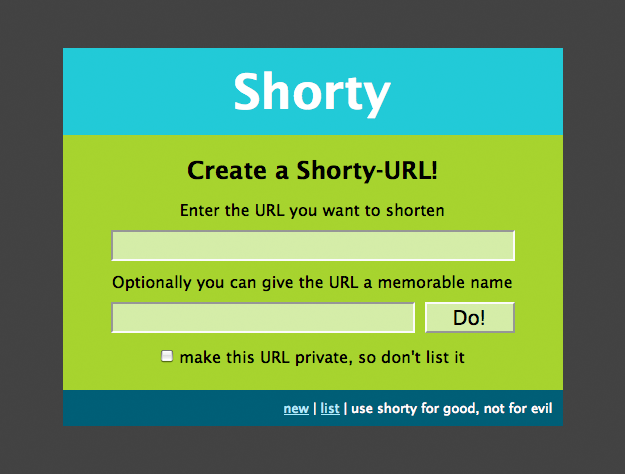
And we can inherit from this base template in our templates/new.html:
{% extends 'layout.html' %}
{% block body %}
<h2>Create a Shorty-URL!</h2>
{% if error %}<div class="error">{{ error }}</div>{% endif -%}
<form action="" method="post">
<p>Enter the URL you want to shorten</p>
<p><input type="text" name="url" id="url" value="{{ url|e(true) }}"></p>
<p>Optionally you can give the URL a memorable name</p>
<p><input type="text" id="alias" name="alias">{#
#}<input type="submit" id="submit" value="Do!"></p>
<p><input type="checkbox" name="private" id="private">
<label for="private">make this URL private, so don't list it</label></p>
</form>
{% endblock %}
If you’re wondering about the comment between the two input elements, this is a neat trick to keep the templates clean but not create whitespace between those two. We’ve prepared a stylesheet you can use which depends on not having a whitespace there.
And then a second template for the display page (templates/display.html):
{% extends 'layout.html' %}
{% block body %}
<h2>Shortened URL</h2>
<p>
The URL {{ url.target|urlize(40, true) }}
was shortened to {{ url.short_url|urlize }}.
</p>
{% endblock %}
The urlize filter is provided by Jinja and translates a URL(s) in a text into clickable links. If you pass it an integer it will shorten the captions of those links to that number of characters, passing it true as second parameter adds a nofollow flag.
Now that we have our first two templates it’s time to fire up the server and look at those part of the application that work already: adding new URLs and getting redirected.
Intermission: Adding The Design¶
Now it’s time to do something different: adding a design. Design elements are usually in static CSS stylesheets so we have to put some static files somewhere. But that’s a little big tricky. If you have worked with PHP so far you have probably noticed that there is no such thing as translating the URL to filesystem paths and accessing static files right from the URL. You have to explicitly tell the webserver or our development server that some path holds static files.
Django even recommends a separate subdomain and standalone server for the static files which is a terribly good idea for heavily loaded environments but somewhat of an overkill for this simple application.
So here is the deal: We let our application host the static files, but in production mode you should probably tell the apache to serve those files by using an Alias directive in the apache config:
Alias /static /path/to/static/files
This will be a lot faster.
But how do we tell our application that we want it to share the static folder from our application package as /static?. Fortunately that’s pretty simple because Werkzeug provides a WSGI middleware for that. Now there are two ways to hook that middleware in. One way is to wrap the whole application in that middleware (we really don’t recommend this one) and the other is to just wrap the dispatching function (much better because we don’t lose the reference to the application object). So head back to application.py and do some code refactoring there.
First of all you have to add a new import and calculate the path to the static files:
from os import path
from werkzeug import SharedDataMiddleware
STATIC_PATH = path.join(path.dirname(__file__), 'static')
It may be better to put the path calculation into the utils.py file because we already calculate the path to the templates there. But it doesn’t really matter and for simplicity we can leave it in the application module.
So how do we wrap our dispatching function? In theory we just have to say self.__call__ = wrap(self.__call__) but unfortunately that doesn’t work in python. But it’s not much harder. Just rename __call__ to dispatch and add a new __call__ method:
def __call__(self, environ, start_response):
return self.dispatch(environ, start_response)
Now we can go into our __init__ function and hook in the middleware by wrapping the dispatch method:
self.dispatch = SharedDataMiddleware(self.dispatch, {
'/static': STATIC_PATH
})
Now that wasn’t that hard. This way you can now hook in WSGI middlewares inside the application class!
Another good idea now is to tell our url_map in the utils module the location of our static files by adding a rule. This way we can generate URLs to the static files in the templates:
url_map = Map([Rule('/static/<file>', endpoint='static', build_only=True)])
Now we can open our templates/layout.html file again and add a link to the stylesheet style.css, which we are going to create afterwards:
<link rel="stylesheet" type="text/css" href="{{ url_for('static', file='style.css') }}">
This of course goes into the <head> tag where currently just the title is.
You can now design a nice layout for it or use the example stylesheet if you want. In both cases the file you have to create is called static/style.css
Part 6: Listing Public URLs¶
Now we want to list all of the public URLs on the list page. That shouldn’t be a big problem but we will have to do some sort of pagination. Because if we print all URLs at once we have sooner or later an endless page that takes minutes to load.
So let’s start by adding a Pagination class into our utils module:
from werkzeug import cached_property
class Pagination(object):
def __init__(self, query, per_page, page, endpoint):
self.query = query
self.per_page = per_page
self.page = page
self.endpoint = endpoint
@cached_property
def count(self):
return self.query.count()
@cached_property
def entries(self):
return self.query.offset((self.page - 1) * self.per_page) \
.limit(self.per_page).all()
has_previous = property(lambda x: x.page > 1)
has_next = property(lambda x: x.page < x.pages)
previous = property(lambda x: url_for(x.endpoint, page=x.page - 1))
next = property(lambda x: url_for(x.endpoint, page=x.page + 1))
pages = property(lambda x: max(0, x.count - 1) // x.per_page + 1)
This is a very simple class that does most of the pagination for us. We can pass at an unexecuted SQLAlchemy query, the number of items per page, the current page and the endpoint, which will be used for URL generation. The cached_property() decorator you see works pretty much like the normal property() decorator, just that it memorizes the result. We won’t cover that class in detail but basically the idea is that accessing pagination.entries returns the items for the current page and that the other properties return meaningful values so that we can use them in the template.
Now we can import the Pagination class into our views module and add some code to the list function:
from shorty.utils import Pagination
@expose('/list/', defaults={'page': 1})
@expose('/list/<int:page>')
def list(request, page):
query = URL.query.filter_by(public=True)
pagination = Pagination(query, 30, page, 'list')
if pagination.page > 1 and not pagination.entries:
raise NotFound()
return render_template('list.html', pagination=pagination)
The if condition in this function basically ensures that status code 404 is returned if we are not on the first page and there aren’t any entries to display (Accessing something like /list/42 without entries on that page and not returning a 404 status code would be considered bad style.)
And finally the template:
{% extends 'layout.html' %}
{% block body %}
<h2>List of URLs</h2>
<ul>
{%- for url in pagination.entries %}
<li><a href="{{ url.short_url|e }}">{{ url.uid|e }}</a> »
<small>{{ url.target|urlize(38, true) }}</small></li>
{%- else %}
<li><em>no URls shortened yet</em></li>
{%- endfor %}
</ul>
<div class="pagination">
{%- if pagination.has_previous %}<a href="{{ pagination.previous
}}">« Previous</a>
{%- else %}<span class="inactive">« Previous</span>{% endif %}
| {{ pagination.page }} |
{% if pagination.has_next %}<a href="{{ pagination.next }}">Next »</a>
{%- else %}<span class="inactive">Next »</span>{% endif %}
</div>
{% endblock %}
Bonus: Styling 404 Error Pages¶
Now that we’ve finished our application we can do some small improvements such as custom 404 error pages. That’s pretty simple. The first thing we have to do is creating a new function called not_found in the view that renders a template:
def not_found(request):
return render_template('not_found.html')
Then we have to go into our application module and import the NotFound exception:
from werkzeug.exceptions import NotFound
Finally we have to catch it and translate it into a response. This except block goes right before the except block of the HTTPException:
try:
# this stays the same
pass
except NotFound, e:
response = views.not_found(request)
response.status_code = 404
except HTTPException, e:
# this stays the same
pass
Now add a template templates/not_found.html and you’re done:
{% extends 'layout.html' %}
{% block body %}
<h2>Page Not Found</h2>
<p>
The page you have requested does not exist on this server. What about
<a href="{{ url_for('new') }}">adding a new URL</a>?
</p>
{% endblock %}
Outro¶
This tutorial covers everything you need to get started with Werkzeug, SQLAlchemy and Jinja and should help you find the best solution for your application. For some more complex examples that also use different setups and ideas for dispatching have a look at the examples folder.
Have fun with Werkzeug!