One Code Styleguide Per Programming Language Is Not Silly
I love Python but there are things where I look at Ruby or Java and want to switch right away. What do have Ruby and Java in common? Nearly all of their libraries follow the same function/method/class naming conventions. foo_bar_baz in Ruby and fooBarBaz in Java. In Python there we have that PEP8 thing, but not even the standard library is PEP8 compatible. Many people tell me that not having the same naming guidelines for all libraries is a problem. I would argue that different naming guidelines among different libraries is a bigger problem than different indentation etc.
The reason for that is that in Python we often subclass clases from other libraries. Just take the threading module as example. Now we are forced to use different names in your own libraries/code too. Now one has to start thinking about the names of methods. (Is is get_some_foo() or some_foo or getSomeFoo()). It becomes even worse if you use mixin classes with one styleguide in a subclass of a class with a different one. I’ve seen people using the `DictMixin` in classes with camel case method names. But even the lowercase names are not coherent. Is it iteritems or iter_items? This example might be answered easily because I never saw iter_items but I saw countless occurrences of both getcurrentuser and get_current_user.
The more different name styles in a code the more I have to use dir(), help(), external documentation or the ipython source introspection. And that’s not the fault of the library developers, it starts with the python language itself. The internal types are all lowercase although they are classes. It’s true that this is because of backwards compatibility (when dict, list and others were just functions) but a big language change like Python3 would have made changing some of those names possible.
</rant>
pretty, a python pprint successor
The ubuntuusers team acquired two new webdesigners this week and the first thing that they missed was a var_dump replacement. In fact that thing is really missing. Python does have a pprint library but it’s not extensible. Impossible to dump normal objects.
I worked today on a port of ruby’s pp library (wanted to call it pp, but that’s already reserved by parallel python). Check it out in the cheeseshop: pretty.
Classes can implement __pretty__ to prettyprint their structure.
I would love to see that as replacement for the builtin pprint library which is impossible to extend. pretty is not yet 100% backwards compatible, some reprs look different, but that’s extensible. Check out the module docstring for some examples.
Female Nicknames
* Blindraven (n=tony@…optusnet.com.au) has joined #ubuntuusers-webteam
[15:46] <Blindraven> ><
[15:47] * juliux (n=juliux@ubuntu/member/juliux) has joined #ubuntuusers-webteam
[15:47] <mitsuhiko> hi juliux
[15:47] * Blindraven ponders
[15:47] <juliux> hi mitsuhiko
[15:48] <Blindraven> lol i join, nothing. you join with a remotely
female *ish* name and you get a hello.. LOL
[15:48] * Blindraven (n=tony@…optusnet.com.au) has left #ubuntuusers-webteam
just for the record: julius is not female ;-)
Rails Motivation

via __doc__
Pygments 0.9 – Herbstzeitlose Released
The new version of Pygments is out now. The changelog is once again quite long and a couple of new lexers were added:
- Erlang
- ActionScript
- Literate Haskell
- Common Lisp
- Various assembly languages
- Gettext catalogs
- Squid configuration
- Debian control files
- MySQL-style SQL
- MOOCode
Some old lexers got updates too:
- Greatly improved the Haskell and OCaml lexers.
- Improved the Bash lexer’s handling of nested constructs.
- The C# and Java lexers exhibited abysmal performance with some input code; this should now be fixed.
- The IRC logs lexer is now able to colorize weechat logs too.
- The Lua lexer now recognizes multi-line comments.
- Fixed bugs in the D and MiniD lexer.
There are also two new formatters. One that outputs SVG documents and a terminal formatter that uses 256 different colors if the terminals support that. There is also a new style which resembles the vim7 default style.
For the full list of changes have a look at the changelog. You can download pygments from the download page. Happy coloring!
About Bug-Fixing and Politeness
It took less than a day. And yes I was an asshole. I can’t blame the django team for fixing things too slow because being Python’s biggest framework you can break existing code easily and fixes often requires careful consideration.
All in all I’m very happy with django and love using it, but the trac always gives me a feeling I cannot really describe. If you query open tickets you can find around 800 of them and tickets I posted so far never got real attention. However that’s not a big problem because most of them where proposals or feature requests.
Two days ago someone posted that URL bug in the IRC Channel and I bookmarked it. I thought that someone of the developers would have the timeline in the RSS reader and fix that. Yesterday I then added a patch that ignores malformed unicode in those URLs and thought I could get that fixed quickly if I sent the link to the ticket to ubernostrum and got as response something like: “that requires discussing on the mailing list, I’m not sure if ignoring is the correct behavior.” And I guess my answer was something like “I’ve better things to do”.
That and the following blog post was just rude and unacceptable. I promise that I won’t do that again :-)
disclaimer: Europe/Vienna
Counting days
Let’s see how long it takes until a rather severe bug gets its patch applied.
said bug is this one: http://code.djangoproject.com/ticket/5738
update: fixed „its“
A Band is more than a Frontman
A band is much more than the man/woman that is in the center of all fan art of a band. Much more. Just take Dream Theater as an example. La Brie is certainly a good singer but not the center of the band. The center are without a doubt Petrucci and Portnoy. And there are other bands out there that make great music but you might not know the names of the other band members.
One example was Nightwish. Until they kicked out their old frontwoman. And it was certainly a good choice because If you listen to their new album they haven’t lost anything. Tarja was never the kind of musician that wrote the music. But she earned all the fame.
And the new album certainly rocks. Although Tarja might be pissed now, but Anette does a very good job and fits into the arrangement perfectly. So if you were a Nightwish listener until Tarja left, give the new album a try.
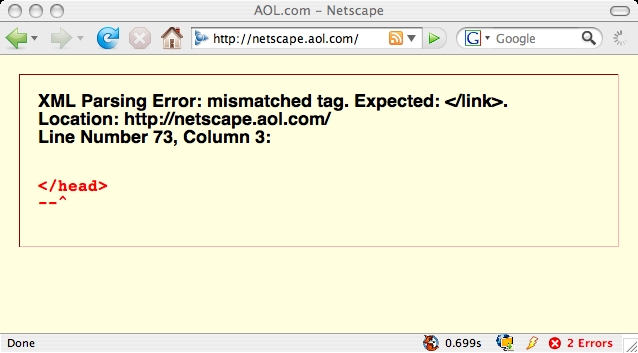
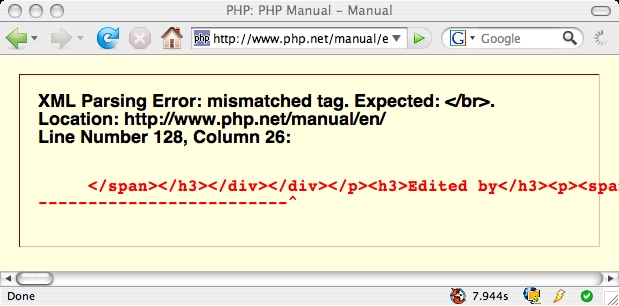
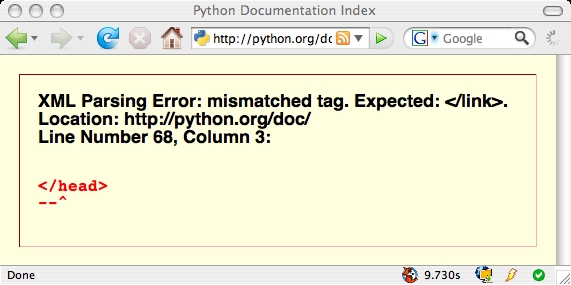
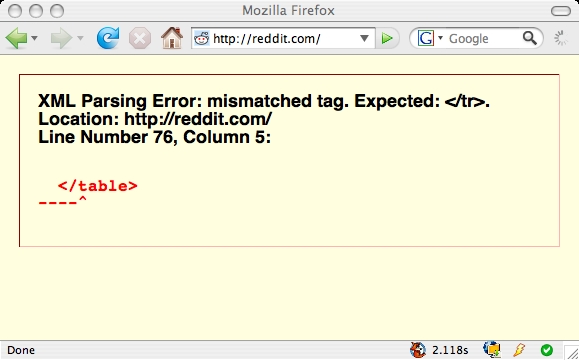
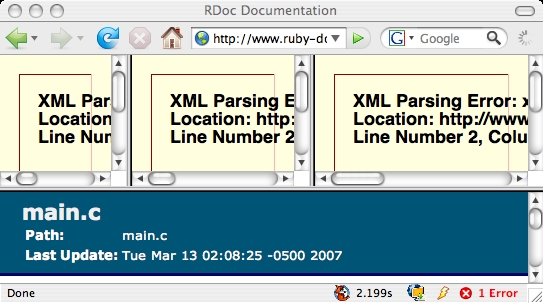
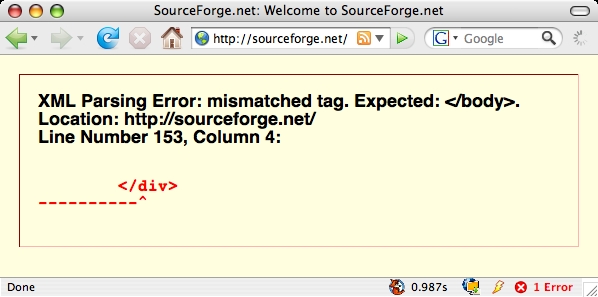
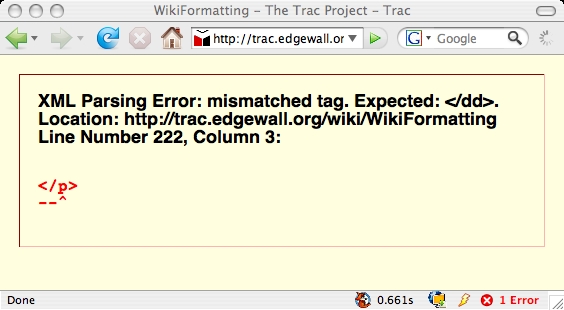
Abusing XHTML
As small resumption to my previous post about XHTML/HTML here a small list of websites using XHTML that break when rendered on a browser in XHTML mode:
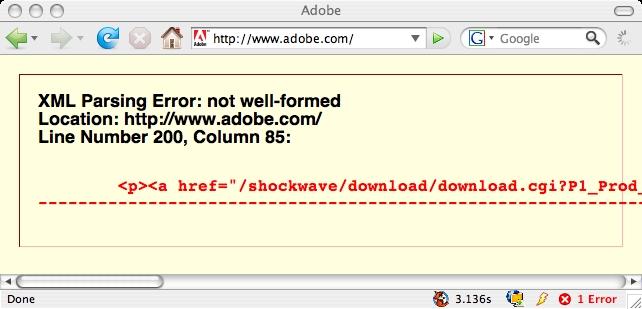
- adobe
- alistapart (although not everywhere)
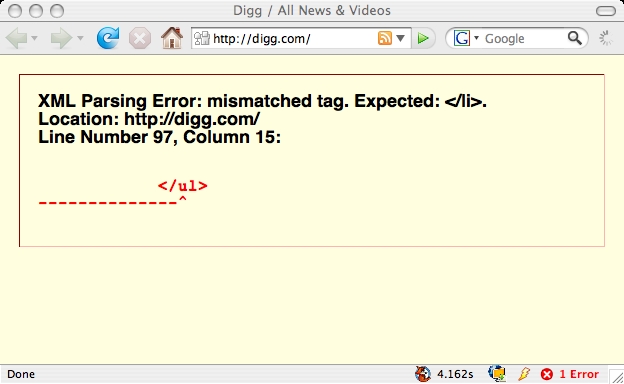
- digg.com
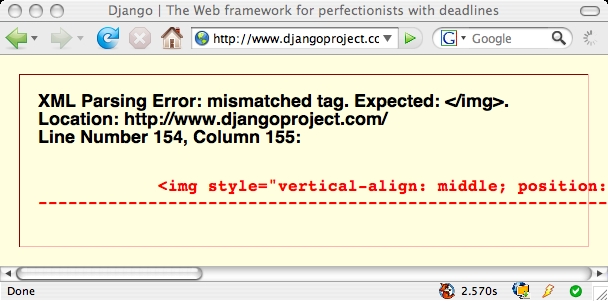
- django webpage
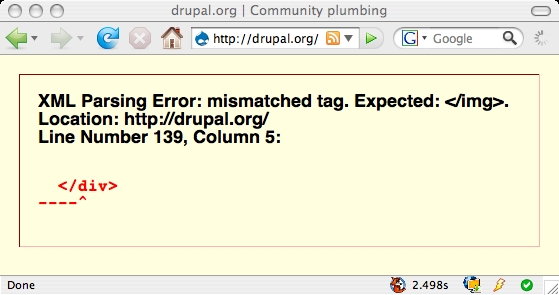
- drupal webpage
- netscape portal
- php documentation
- python webpage
- ruby documentation
- sourceforge
- trac
Not that all my XHTML pages are valid, but if they fail… How should browser vendors implement XHTML if that would break the internets?
Doctype Woes (back to HTML4)
At the moment I’m working together with the rest of the webteam of the ubuntuusers Team on the new portal of ubuntuusers.de based on django. One of the things we will do is consolidating all templates. And while doing so we have to decide to use an HTML/XHTML standard which we will use including the correct mimetype and doctype.
And selecting that is the hardest part because once you’ve decided on something you have to live with the consequences and cannot really change. For example HTML and XHTML have a slightly different DOM or different rules for CSS (CSS for example has an exception that allows background colors on the body-tag to affect the whole page, this exception does not exist for XHTML). Without a doubt many people use XHTML in a wrong way. Just have a look how many people serve their webpages as text/html and only use HTML semantics. They break if you serve them as application/xml+xhtml or render in a wrong way.
But why does XML and SGML have different semantics? SGML itself was created long ago (I assume IBM has something to do with it, at least it’s predecessor was created there) and is an insane specification. At least that’s what the web told me. I cannot tell you if that’s true or not because the standard itself is not available without paying for it :-/
From what sources tell me XML is an subset of SGML. I wonder how that’s possible tough, because there are syntactic elements that in my opinion are not compatible. For example clash XML’s self closing tags with null end tags in SGML:
XML <br /><br />
SGML: <p/This is some text in a paragraph/
Because the slash has a special meaning in tags in SGML it clashes with the closing slash of XML tags. Also SGML is apparently case insensitive where XML is not. Maybe I’m also wrong there and that part is up to the DTD, but quite frankly. I don’t care. I don’t even are about clashing slashes in tags because no browser implements the correct SGML behavior. And if they would do, we would all see invalid output because the web is not valid. It’s not and it will never be.
But what’s indeed ridiculous is that it’s incredible hard to write pages that are semantical and syntactical correct to both HTML4 and XHTML. However you have to make your documents compatible to both if you want to your page to be valid XHTML and render correctly. The reason is that no browser today selects the render mode by Doctype, and even if they would do, other browsers would break then on the huge number of pages that incorrectly use XHTML.
XML is strict, very strict. Syntactical errors appear as big red error messages. I for myself have to work on the wiki markup for the new portal and one of the things I have to deal with is balancing elements. That is possible and simple, but what’s harder is adding paragraphs without breaking things. And that’s not that easy because not every element is allowed in a paragraph and a paragraph cannot be mixed with every element thanks to inline versus block elements.
Even HTML5 disallows that mixing of different element types but at least it doesn’t complain. Sure, I could send the output through a validator and tell the user that his markup is bullshit and he should correct it. But I won’t do that. Users give a fuck about their markup. And I cannot bloat the parser more than it is now. Server resources are limited and additional validation for such a high traffic site is nearly impossible.
Fortunately browsers will never show you those errors because they parse XHTML with their tagsoup parser they use for HTML too. Even tough, if we cannot ensure that all of our pages are valid XML and XHTML we are not allowed to use the doctype because it would break browsers that support XHTML.
While this is hard for webdesigners and especially for programmers that want to create parsers that generate XHTML it’s an even harder job for the developers of browsers. In the end they have to have two independent parsers for HTML and XHTML. This makes it hard enough for the big browser vendors Microsoft, Mozilla, Opera and Apple, but even harder if you are new to the market and want to ship your own one. Because you not only have to be compatible with the new XHTML standard, but also the old HTML one. Nobody will translate all the old documents to XHTML I’m sure ;-)
Details about the issues are summarized here:
- The <?xml> prolog, strict mode, and XHTML in IE — Chris Wilson, Microsoft
- Understanding HTML, XML and XHTML — Surfin’ Safari Weblog
- Sending XHTML as text/html Considered Harmful — Ian Hickson
- Quick Guide to XHTML — Anne van Kesteren
- The Road to XHTML 2.0: MIME Types — Mark Pilgrim
Without a doubt we will have fun with XHTML in the future. Probably the web stays like it’s today, we will still use the tag soup parsers, people will write XHTML that is HTML in fact and browsers will interpret it like that.
For me the decision is HTML4 at the moment, with the subset that is valid for both HTML4 and HTML5. That could make it easier for transition once the standard is ready (and I hope it’s earlier than 2022) and it’s good idea now too. Who needs an u-Tag anyway?
 2004 – 2007 ubuntuusers.de • Einige Rechte vorbehalten
2004 – 2007 ubuntuusers.de • Einige Rechte vorbehalten
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}